

Teach Azure to Speak with Azure Cognitive Services Text to Speech Services
Nov 24, 2020 • 11 Minute Read
Introduction
Modern user interfaces do not stop at the keyboard and mouse. Today we can interact with apps using vision, gestures, and even speech. It doesn't make much sense to talk to a computer, unless it can talk back. This is referred to as text to speech. If this sounds like a hard problem to solve, it is. However, Microsoft Azure offers the Speech service to help teach computers to speak. This guide will discuss getting started with the Microsoft Azure Speech service using the C# programming language. Keep in mind that Azure Cognitive Services support SDKs for many languages including C#, Java, Python, and JavaScript, and there is even a REST API that you can call from any language.
Setup
As with all Azure Cognitive Services, before you begin, provision an instance of the Speech service in the Azure Portal. The Speech service does much more than text to speech. It can also invert the concept and transcribe audio files. The same Speech service is used for both.
Create a new Speech service instance, choose an Azure subscription and data center location, and choose or create a new resource group. For the pricing tier, the free F0 option will suffice for experimentation.
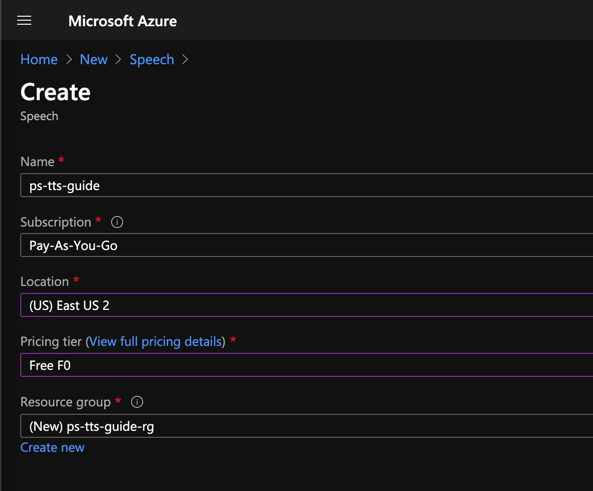
The free tier will allow you to process five million characters per month. There is also the option to generate speech using neural voices that sound more like human voices but are more computationally intensive. The free quota for neural voices is therefore lower, just 500 thousand characters per month. We'll see the difference between standard and neural voices later in the guide. For more details on the quotas and pricing of the free and paid tiers, see the Azure Speech service documentation.
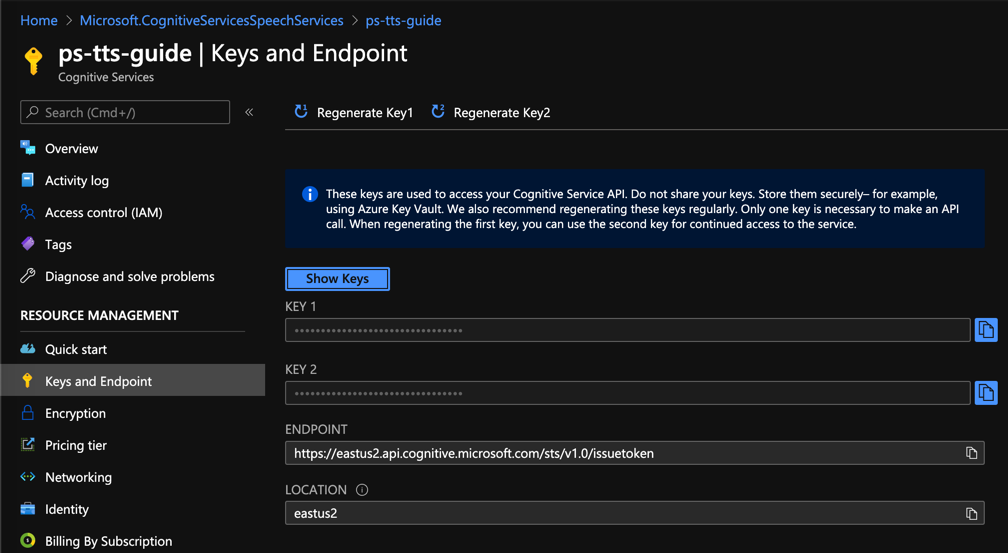
After the instance is provisioned, you'll see the API keys and endpoint you'll use to access the service in the Keys and Endpoint menu on the left.
Getting the SDK Ready
The SDK is distributed as a NuGet package. Add Microsoft.CognitiveServices.Speech to a C# project to install the SDK using the dotnet tool at the command line:
dotnet add package Microsoft.CognitiveServices.Speech --version 1.14.0
The most current version, when this guide was created, was 1.14.0.
To authenticate with the SDK, you'll need to create an instance of SpeechConfig found in the Microsoft.CognitiveServices.Speech namespace.
using Microsoft.CognitiveServices.Speech;
Use the endpoint and one of the API keys from the Azure portal to create a new instance with the static FromEndpoint method:
var speechConfig = SpeechConfig.FromEndpoint("{endpoint}", "{apikey}");
You'll also need an AudioConfig instance from the Microsoft.CognitiveServices.Speech.Audio namespace.
using Microsoft.CognitiveServices.Speech.Audio;
// ...
var audioConfig = AudioConfig.FromWavFileOutput("demo.wav");
There are several ways to create an AudioConfig including a stream or directly to speaker. For this demo, the easiest will be to create a .wav file. The FromWavFileOutput method accepts the path to the generated .wav file.
To generate the speech file, create a SpeechSynthesizer from the SpeechConfig and AudioConfig:
var speechSynthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
Finally, call the SpeakTextAsync method on the SpeechSynthesizer and provide a string that will be used to generate a .wav file. This method needs to be awaited.
await speechSynthesizer.SpeakTextAsync("Peter Piper picked a peck of pickled peppers.");
You can listen to the generated .wav file on GitHub.
Customizing the Voice
By default, the SpeechConfig uses a voice with a name en-US-JessaRUS. This is a female voice. To get a male voice, set the SpeechSynthesisVoiceName property of the SpeechConfig to en-US-GuyRUS.
speechConfig.SpeechSynthesisVoiceName = "en-US-GuyRUS";
You can listen to this voice on GitHub.
There are more than 75 voice in over 45 languages available. A complete list can be found in the Azure documentation.
Using SSML
You can generate even more realistic voices using SSML, or Speech Synthesis Markup Language. This is an XML grammar that is not specific to the Speech service. It's a standard that is used across Azure, AWS, Google Cloud and more. Here is a sample SSML document:
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-GuyRUS">
I live in the zip code 10203.
</voice>
</speak>
The <speak> and <voice> elements are boilerplate for all SSML. The name attribute is one of the supported voices from the previous section. The SSML is then parsed by the SpeakSsmlAsync method.
SpeechSynthesizer ssmlSynthesizer = new SpeechSynthesizer(speechConfig, null);
var ssmlResult = await ssmlSynthesizer.SpeakSsmlAsync(ssml);
var audioDataStream = AudioDataStream.FromResult(ssmlResult);
await audioDataStream.SaveToWaveFileAsync("ssmldemo.wav");
Notice that the ssmlSynthesizer does not need an AudioConfig. Also, the results are retrieved from AudioDataStream. You can hear the file on GitHub.
It also pronounces the zip correctly as "one zero two zero three" and not "ten thousand two hundred and three." What happens if we use the same number, in a different context?
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-GuyRUS">
I won 10203 dollars in the sweepstakes!
</voice>
</speak>
Listen to the file on GitHub. This time, we expect the same value to be pronounced as "ten thousand two hundred and three." But by default, it is not. To get the correct speech, use the <say-as> element and set the interpret-as attribute to cardinal.
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-GuyRUS">
I won <say-as interpret-as="cardinal">10203</say-as> dollars in the sweepstakes!
</voice>
</speak>
Now the number is pronounced the way we expect. Here is the correct .wav file on GitHub.
There are times when you may want to introduce a pause. You might want a lengthy break after the first sentence in this sample before delivering the 'punchline'.
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-GuyRUS">
I got the new XBox Series X for 1/2 off! <break time="2500ms" /> Just kidding.
</voice>
</speak>
Here is the generated .wav file on GitHub. The time attribute of the <break> element includes silence for 2,500 milliseconds. You can also use seconds for example 4s. Also, note in the .wav file that "1/2" is correctly pronounced as "one half."
Neural Voices
It sounds okay, but it doesn't sound realistic. This is where neural voices come in. Neural voices are generated using neural networks and it's very tough to tell they are not actual humans. Since they are generated using neural networks, they are much more computationally intensive and thus cost a little more. But the results are worth it. Currently there are around 65 neural voice, and previews of more are coming soon.
To use a neural voice, simply set the name attribute of the <voice> element in SSML to a neural voice.
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-AriaNeural">
Peter Piper picked a peck of pickled peppers.
</voice>
</speak>
Note: If you generate a .wav file that is only a few bytes, check the location where you created the instance of the Speech service. The neural voices are only available in East US, South East Asia, and West Europe.
Here is the .wav file generated on GitHub.
There are more options for customizing the speaking style of a neural voice. For example with the <mstts:express-as> element you can set the style attribute to a relaxed tone for chatting, an excited tone, and even styles for newscasts and customer service. You'll need to include the mstss namespace in the markup.
<speak version="1.0"
xmlns="https://www.w3.org/2001/10/synthesis"
xmlns:mstts="https://www.w3.org/2001/mstts"
xml:lang="en-US">
<voice name="en-US-AriaNeural">
<mstts:express-as style="chat">
Peter Piper picked a peck of pickled peppers.
</mstts:express-as>
</voice>
</speak>
This is the chat style and the customerservice style. Styles are dependent upon the neural voice that you are using. Check the Azure documentation for the complete list.
Conclusion
There are other options for working with the Speech service. It provides a special API for long texts such as books. You can submit custom lexicons and add prerecorded audio to the generated ones. Azure Cognitive choices should always be your first choice when generating speech for apps. It works with multiple languages. The cost is more affordable than generating voices yourself. Don't forget the quality of the neural voices, especially the options for tuning them. And the service is accessible on any platform and any device, making it possible for any app to speak its mind.
Thanks for reading!


Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.