


Redis as a Dynamic Interconnecting Datastore
Learn about Redis as a dynamic interconnecting datastore and how to host a Redis client in your application and how the request is sent to the Redis server.
Jan 10, 2019 • 13 Minute Read
Introduction
“Context and memory play powerful roles in all the truly great meals in one's life.” Anthony Bourdain, Chef
Yes, I know. He (Anthony) is talking about meals, and we are talking about software development. But there is slight similarity. Sometimes our data, passing through our software parts, goes through specific transformations, getting passed around according to a very specific algorithm. The output of that data will eventually become our output, or “meal”, so to speak.

The output of each computation step could either be the final output of our processing or the input for the next step in processing.
Our current processing step is referred to as our state. Any data we have computed to this point is our state data.

Now, the state data might go through processing, in the current processing state, with different parameters each time (i.e. current date and time, user id). These parameters are referred to as context. It is very common that a message either contains it’s context or has a hint about how to resolve the context. If the context is being passed inside the message, then there is no real “resolving” step.

Each processing state might require access to the context of the data being passed to it, in order to fulfill its designed purpose.

So context resolution is the process in which a running software component receives the context relevant to the computation it is about to perform.
In some common cases, such as web applications, that context could be the session established per user — when the user logged into our system — or it could contain any metadata about the information being passed to us.
Working with software systems these days is quite different from how it was several years ago. Various software components might change our context as time passes. These components need access to a shared resource to which they can simultaneously refer and consume (read / write) the context they so need.
Redis provides such capabilities.
So … What is Redis?
Redis, originally created by Salvatore Sanfilippo, was named “Redis” to reflect its original purpose to provide “Remote Dictionary Server”. It was initially released on GitHub in 2010 and has undergone many new releases since.
In this guide, I will provide a birds-eye view of Redis, as it is today — in my opinion, it is more than a remote dictionary server.
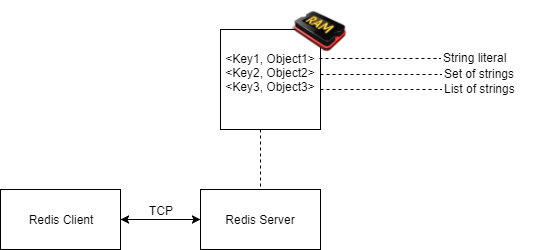
You, the Redis consumer, will be hosting a Redis client in your application. That client will communicate any request given to it to the Redis server (or servers, when deployed as a cluster). This communication will be performed over a simple and efficient protocol, over TCP.
The requests we pass on to Redis will be mostly CRUD (Create, Read, Update, Delete) operations in the form <Key, Object>, where Object can take on the form of any supported data type, such as a string, a list, an ordered list or a set.
For example, the following information was persisted in Redis for demonstration (I am using the Open source Redis commander user interface hosted on docker):
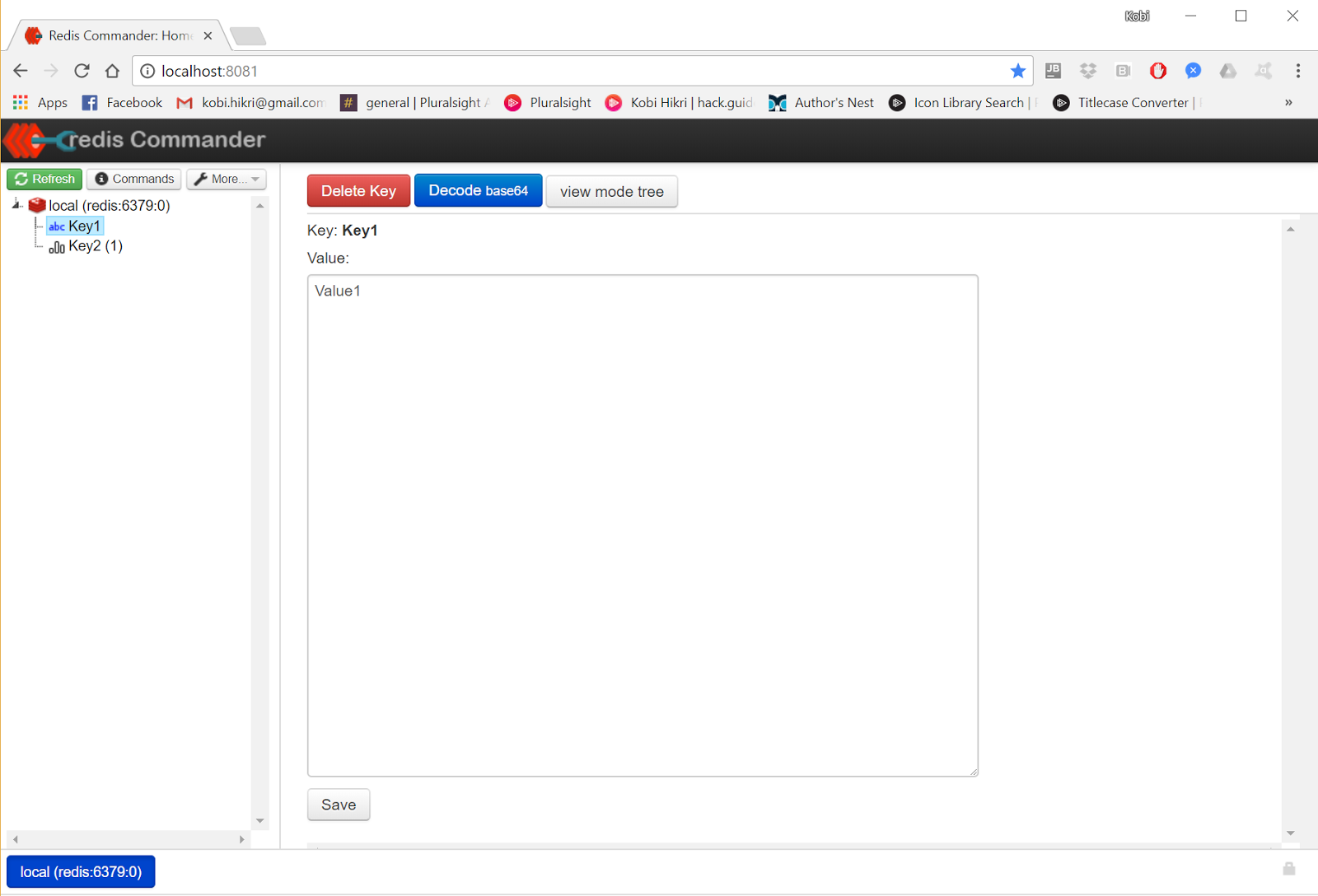
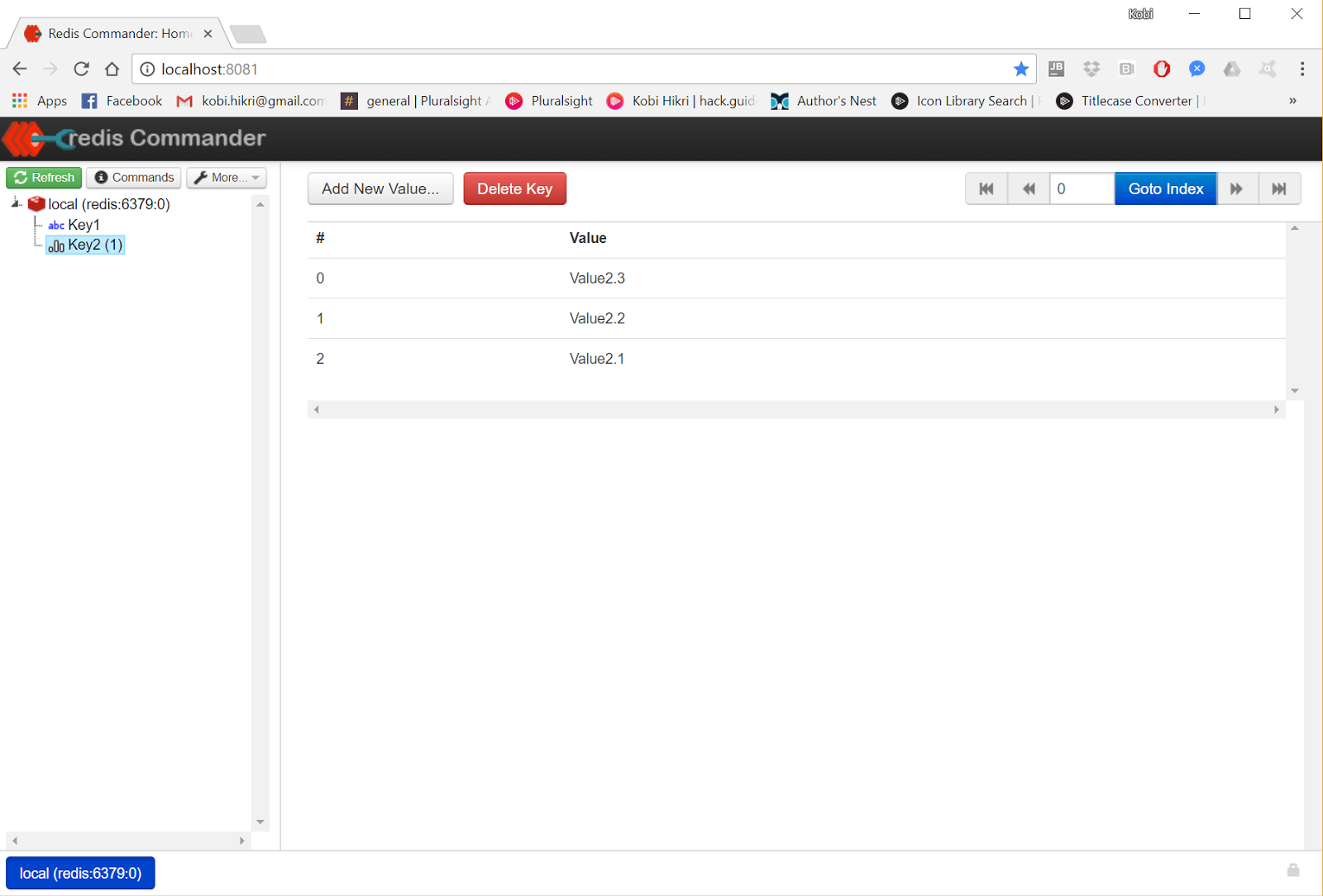
In the image above, you can see a simple Key, Value pair. The next screenshot shows a list of values associated with the same key.
We can optionally define an expiration time for any key we store in Redis. This expiration time will be accurate to the millisecond (version >= 2.6). Expired keys (and their values) will be deleted automatically once they’ve expired.
It’s important to note that what makes Redis very interesting as a centralized Cache / Datastore / Synchronized data provider is that it is blazing fast, mostly because all data is persisted in-memory. By default, Redis will also persist all data to non-volatile storage, a setting that can be configured, and it also supports replication and high-availability — though this article won't discuss those features in much depth.
Let’s observe some use cases and see some code to better understand the technology.
Using Redis As a Synchronized Cache Mechanism
Redis is commonly used as a distributed cache. Having more than one process in our application, Redis can be a “central point of reference” to all processes (optionally across more than one machine).
Having a central, single representation of our systems data allows us to safely implement our logic, “knowing” that at any given point in time per input message, all processes “looking” at a specific piece of information (e.g. context) will “see” the same information.

In the diagram above, we can see two processes which each received input message #1 at the exact same time. Both processes are requesting the message context from Redis and will receive the exact same context!
A different situation could also occur. It might be the case that the output of a single process is the input for another. In such a case, the times t1 and t2 will be different (t2 > t1), resulting in an optionally different context for each process.

For example, assume our computation begins as a user logs into our system. Before the user performs any additional operations, we already “know” something about that user (i.e. name, login location, and historical activities in our system).
Some of that information might be used across our computation, probably by different processes (hosted on different machines).
In such a case, we might do wisely to cache that context information in-memory and have it provided quickly to any consuming process.

That is very helpful indeed. As long as we can make sure that our data is properly synchronized.
Remember that point about having a single representation of our context at a given point in time? Well, it appears that making sure this is true is not a simple a task when dealing with concurrent systems. Multiple processes might access the same data at the same time. Some might try to modify it.

Let's see how Redis allows us to deal with concurrent data consumption.
A Distributed Locking Mechanism at Your Disposal
Redis supports and promotes the uses of the Redlock algorithm, in order to implement distributed locking of resources. The algorithm is an interesting one as it presents a deadlock free approach to the concept of locking.
Now, if you’ve studied computer science, you might know that the presentation of a critical section to your application — in our case, that is the code accessing our locked data — inherently presents the possibility of a deadlock.
So how can the Redis team claim that their approach is deadlock free?
Because the concept “deadlock free” refers to the process of obtaining and releasing a lock holistically.
It’s true that if a specific client acquired a lock, other clients trying to consume that data get blocked.
However, using the Redlock algorithm, that lock is guaranteed to eventually be released, making the algorithm deadlock free.

Every successful lock operation has a timeout that expires even if the locking client crashes without gracefully releasing the locked resource.

Sample Context Interaction Implementation
Here is some Python sample code, demonstrating how one process writes to the context while another process tries to read from the context:


Simple, right?
Please notice that our request to acquire a lock can be denied at a given point in time. It is then the responsibility of the lock requesting client to perform a retry.
Some Redlock implementations have that retry mechanism embedded:

Excellent. We have now learned how to safely access our distributed cache with concurrent consumers trying to access or modify it.
Let's now look at another interesting Redis use-case.
Interprocess Communication With Redis
Suppose we would like our process to communicate with the “outer world”. We would need access to an interprocess communication mechanism.
Redis has very simple and efficient Publisher/Subscriber interprocess communication abstraction built into it already.
With this abstraction, we can decouple our processes from any knowledge about “Who” produces or consumes any specific message.
A process, then, is only responsible for processing messages arriving at its “gate”.

Let’s see how one would implement such a mechanism using Redis.
Sample Publisher/Subscriber Mechanism Implementation
First, observe how we can publish data on a specific channel:

Next, check out how a client can consume messages from this channel:

Simple, right?
The next screenshot demonstrates how a client consumes information from several channels:

And, to conclude this demonstration, let's see a client that consumes information from several channels, but this time we will specify the channels of interest as a pattern.
Again, here is the publisher code, publishing to three different channels on every loop iteration:

And here is the subscribing client, but this time subscribed to channels which name complies to the pattern specified:

In Conclusion
To summarize, we began this discussion with a point about context, and why it is important that our context has a discrete value or state at any point in time.
Then, we covered how the concept of a context features in distributed systems, particularly when it comes to synchronized caches. As part of this, we examined locking and how Redis “solves” the distributed context problem using the Redlock algorithm.
Finally, we examined another popular use-case for Redis — the Publisher/Subscriber messaging model implementation. In covering this, we examined the concept of publishing and demonstrated with Python code.
Please notice that I intentionally left out any DevOps-related discussion about clustering/high availability and fault-tolerance. I intend to write about these topics in a separate article!
I hope you found this Redis tutorial informative and engaging. Please leave any comments and feedback in the discussion section below, and don't forget to add this guide to your favorites. Thank you for joining me,
Kobi.

Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.

