


Importance of Text Pre-processing
Data that is unstructured or contains unusual text and symbols needs to be cleaned and pre-processed before it can be used in machine learning models.
Oct 5, 2020 • 12 Minute Read
Introduction
If, as they say, "the customer is king," then customer feedback is vital for any organization, and even to the government of any country. Feedback has the power to make or break a government or organization. The insights gained through public review analysis can influence strategy for better performance.
The kind of data you get from customer feedback is usually unstructured. It contains unusual text and symbols that need to be cleaned so that a machine learning model can grasp it. Data cleaning and pre-processing are as important as building any sophisticated machine learning model. The reliability of your model is highly dependent upon the quality of your data.
Getting Started
Steps in pre-processing depend upon the given task and volume of data. This guide will cover main pre-processing techniques like leaning, normalization, tokenization, and annotation.
Before going further with these techniques, import important libraries.
import numpy as np
import pandas as pd
import re
import string
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem.porter import *
from nltk.stem.wordnet import WordNetLemmatizer
Cleaning and Removing Noise
It helps to get rid of unhelpful parts of the data, or noise, by converting all characters to lowercase, removing punctuations marks, and removing stop words and typos.
Removing noise comes in handy when you want to do text analysis on pieces of data like comments or tweets. The code in the following sections will be helpful to get rid of the text that interferes with text analysis.
This example uses simple text for an easy walkthrough. You may also add .txt files with paragraphs, or paste/write them directly. Refer to the alternative code below.
Lowercase
You might be thinking, "What should be my approach when capitalization is at the beginning of the sentence or in proper nouns?" There is a common approach to lowercasing everything for the sake of simplicity. It helps to maintain the consistency flow during the NLP tasks and text mining. The lower() function makes the whole process quite straightforward.
def lowercase(intext):
return intext.lower()
#Alternatively:
#orig =data.raw(r'file.text') # read raw text form orignal file
#sent = data.sents(r'file.txt') #brake parah into sentance
#bwords = data.words(r'file.text')#break parah into words
intext = input('Your-Text:')
clean_text = lowercase(intext)
print('\nlowercased:',lowercase(clean_text))

The punctuation to the sentence adds up noise that brings ambiguity while training the model.
Punctuations
Let's check the types of punctuation the string.punctuation() function filters out. To achieve the punctuation removal, maketrans() is used. It can replace the specific characters' punctuation, in this case with some other character. The code replaces the punctuation with spaces (''). translate() is a function used to make these replacements.
output= string.punctuation
print('list of punctuations:', output)
def punctuation_cleaning(intext):
return text.translate(str.maketrans('', '', output))
print('\nNo-punctuation:',punctuation_cleaning(clean_text))

HTML Code and URL Links
The code below uses regular expressions (re). To perform matches with a regular expression, use re.complie to convert them into objects so that searching for patterns becomes easier and string substitution can be performed. A .sub() function is used for this.
def url_remove(text):
url_pattern = re.compile(r'https?://\S+|www\.\S+')
return url_pattern.sub(r'', text)
def html_remove(text):
html_pattern = re.compile('<.*?>')
return html_pattern.sub(r'', text)
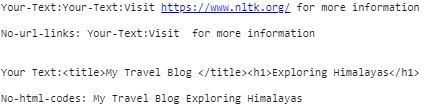
text1 = input('Your-Text:')
print('\nNo-url-links:', url_remove(text1))
text2 = input('Your Text:')
print('\nNo-html-codes:', html_remove(text2))
Spell Checks
This guide uses the pyspellchecker package for spelling correction.
from spellchecker import SpellChecker
spelling = SpellChecker()
def spelling_checks(text):
correct_result = []
typo_words = spelling.unknown(text.split())
for word in text.split():
if word in typo_words:
correct_result.append(spelling.correction(word))
else:
correct_result.append(word)
return " ".join(correct_result)
text = input('Your-Text: ')
print('Error free text:',spelling_checks(text))

Refer to this code to learn how to remove emojis from your text.
NLTK
NLTK stands for Natural Language Toolkit. It is a powerful tool complete with different Python modules and libraries to carry out simple to complex natural language processing (NLP). These NLP libraries act as translators between machines (like Alexa, Siri, or Google Assistant) and humans so that the machines have the appropriate response. NLTK has a large, structured text known as a corpus thatt contains machine-readable text files in a directory produced for NLP tasks. WordNet is a famous corpus reader. Read more about corpus readers here.
Before using the NLTK library, make sure it is downloaded on your system. Use these steps to install NLTK.
Tokenization
Tokenizing is like splitting a whole sentence into words. You can consider a simple separator for this purpose. But a separator will fail to split the abbreviations separated by "." or special characters, like U.A.R.T., for example. Challenges increase when more languages are included. How about dealing with compound words in languages such as German or French?
Most of these problems can be solved by using the nltk library. The word_tokenize module breaks the words into tokens and these words act as an input for the normalization and cleaning process. It can further be used to convert a string (text) into numeric data so that machine learning models can digest it.
Removing Stop Words
English is one of the most common languages, especially in the world of social media. For instance, "a," "our," "for," "in," etc. are in the set of most commonly used words. Removing these words helps the model to consider only key features. These words also don't carry much information. By eliminating them, data scientists can focus on the important words.
Check out the list of the stop words nltk provides.
stopwordslist = stopwords.words('english')
print(stopwordslist)
print('Total:',len(stopwordslist))

text = "A smart kid ran towards the police station when he saw the thieves approaching."
stop_words = set(stopwords.words('english'))
tokenwords = word_tokenize(text)
result = [w for w in tokenwords if not w in stop_words]
result = []
for w in tokenwords:
if w not in stop_words:
result.append(w)
print('Tokenized words: ',tokenwords)
print('No-Stopwords: ',result)

The highlighted words are removed from the sequence. Put in some dummy text and notice the changes.
Normalization
Stemming
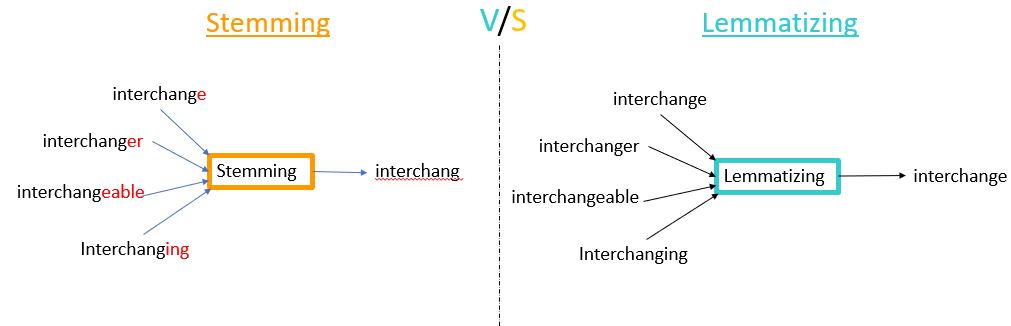
There are many variations of words that do not bring any new information and create redundancy, ultimately bringing ambiguity when training machine learning models for predictions. Take "He likes to walk" and "He likes walking," for example. Both have the same meaning, so the stemming function will remove the suffix and convert "walking" to "walk." The example in this guide uses the PorterStemmer module to conduct the process. You can use the snowball module for different languages.
ps = PorterStemmer()
stemwords = [ps.stem(w) for w in tokenwords]
print ('Stemming-Form:', stemwords)
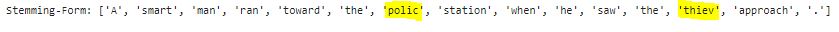
In this example, the words "polic" and "thiev" don't make sense. They have their e and es clipped due to stemming's suffix stripping rule. The Lemmatization technique can address this problem.
Lemmatization
Unlike stemming, lemmatization performs normalization using vocabulary and morphological analysis of words. Lemmatization aims to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma. Lemmatization uses a dictionary, which makes it slower than stemming, however the results make much more sense than what you get from stemming. Lemmatization is built on WordNet's built-in morphy function, making it an intelligent operation for text analysis. A WordNet module is a large and public lexical database for the English language. Its aim is to maintain the structured relationship between the words. The WordNetLemmitizer() is the earliest and most widely used function.
lemmatizer = WordNetLemmatizer()
lemmawords = [lemmatizer.lemmatize(w) for w in tokenwords]
print ('Lemmtization-form',lemmawords)

Use Case
The NLTK corpus reader uses a lexical database to find a word's synonyms, antonyms, hypernyms, etc. In this use case, you will find the synonyms (words that have the same meaning) and hypernyms (words that give a broader meaning) for a word by using the synset()function.
from nltk.corpus import wordnet as wn
for ssn in wn.synsets('aid'):
print('\nName:',ssn.name(),'\n-Abstract term: ',ssn.hypernyms(),'\n-Specific term:',ssn.hyponyms())#Try:ssn.root_hypernyms()

There are three abstract terms for the word "aid". The definition() and examples() functions in WordNet will help clarify the context.
print('Meaning:' ,wn.synset('aid.n.01').definition()) #try any term-eg: care.n.01
print('Example: ',wn.synset('aid.n.01').examples())

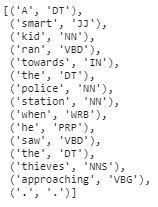
Part of Speech Tagging (POS)
In the English language, one word can have different grammatical contexts, and in these cases it's not a good practice to consider the two words redundant. POS aims to make them grammatically unique.
text_words = word_tokenize(text)
nltk.pos_tag(text_words)
Conclusion
These are key techniques that most data scientists follow before going further for analysis. Many of them have claimed that text pre-processing has degraded the performance of their machine learning model. Hence, combining these tools and techniques is a complex task.
It is not necessary to conduct all of the above techniques. You must understand the type of data you are dealing with and accordingly apply the ones that give the best results. Apply moderate pre-processing if you have a lot of noisy data, or if you have good quality text but a scarcity of data. When the data is sparse, heavy text pre-processing is needed.
Because the input text is customizable, you may try creating your sentences or inserting raw text a file and pre-process it. NLTK is a powerful tool. Machines are learning human languages. We are stepping into a whole new world!
Feel free to reach to me here.


Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.