

Exploring Web Scraping with R
Jul 12, 2020 • 11 Minute Read
Introduction
We live in a digital world where individuals and organizations are significantly impacted by the internet. Data scientists are often required to extract, process, and analyze web data. This is where web scraping comes into the picture as one of the most popular and powerful ways of getting web data from the internet and extracting information from it.
In this guide, you will learn the techniques of web scraping using the powerful programming language R.
Getting Started
The first step is to import the required libraries. You will work with the rvest package for web scraping that is authored and managed by Hadley Wickham. The rvest library has several useful functions for extracting data from the web.
Start by importing the required libraries.
library(rvest)
library(stringr)
library(xml2)
The next step is to create an object that contains the web data you want to parse. In this guide, you will perform web scrapping on an Amazon webpage that sells the product Samsung Galaxy S20 Ultra.
The first line of code below specifies the web address of the site to be scraped, while the second line reads the content from the website and stores it in the object webdata. The read_html() function is used to scrape HTML content from a given URL.
url = https://www.amazon.in/dp/B08444S68Q/ref=pc_mcnc_merchandised-search-12_?pf_rd_s=merchandised-search-12&pf_rd_t=Gateway&pf_rd_i=mobile&pf_rd_m=A1VBAL9TL5WCBF&pf_rd_r=SPDFGAW43YWZW1YZYE1S&pf_rd_p=531f8832-1485-47d3-9dbc-5a9219e94407
webdata = read_html(url)
You have created an object containing the website information, and this object will be used to extract further information. Start by inspecting the text of the website landing page. This is done with the code below, which includes two functions: html_nodes() and html_text().
The html_nodes() function identifies the HTML wrappers, while the html_text() function strips the HTML tags and extracts only the text.
webdata %>%
html_nodes("p") %>%
html_text()
Output:
'Delivery Associate will place the order on your doorstep and step back to maintain a 2-meter distance.' 'No customer signatures are required at the time of delivery.' 'For Pay-on-Delivery orders, we recommend paying using Credit card/Debit card/Netbanking via the pay-link sent via SMS at the time of delivery. To pay by cash, place cash on top of the delivery box and step back.' 'Fulfilled by Amazon indicates that this item is stored, packed and dispatched from Amazon fulfilment centres. Amazon directly handles delivery, customer service and returns. Fulfilled by Amazon items can be identified with an badge. Orders containing items Fulfilled by Amazon worth Rs.499 or more are eligible for FREE delivery. FBA items may also be eligible for faster delivery (Same-Day, One-Day and Two-Day).' 'If you are a seller, Fulfilment by Amazon can help you grow your business. Learn more about the programme.' 'Sign in/Create a free business account ' '\n Find answers in product info, Q&As, reviews\n ' '\n Your question may be answered by sellers, manufacturers, or customers who purchased this item, who are all part of the Amazon community.\n ' '\n Please make sure that you\'ve entered a valid question. You can edit your question or post anyway.\n ' '\n Please enter a question.\n ' 'Galaxy S20 series introduce the next generation of mobile innovation. Completely redesigned to remove interruptions from your view. No notch, no distractions. Precise laser cutting, on-screen security, and a Dynamic AMOLED that\'s easy on the eyes make the Infinity-O Display the most innovative Galaxy screen yet. Use the Ultra Wide Camera to take stunning, cinematic photos with a 123 degree field of vision.\n\n' '\n With Space Zoom bolstered by AI, now you can get close up to the action like never before.\n ' '\n 8K Video Snap revolutionizes how you capture photos and videos\n ' '\n Single Take is essentially burst mode turned beast mode. With revolutionary AI, it lets you shoot for up to 10 seconds and get back a variety of formats — meaning you can choose the best style for the moment without having to reshoot.\n ' '\n In low light, the pro-grade camera system captures multiple photos at once, merging them into one stunning shot with less blur and noise. With larger image sensors and AI, switching to Night Mode means you can shoot night-time scenes clearer.\n ' '\n The HDR10+ certified Infinity-O Display offers an immersive viewing experience.\n ' '\n More playing, less waiting, thanks to powerful RAM and an enhanced processor with advanced AI.\n ' '\n Battery that is powerful as well as intelligent, adjusting to your mobile habits to last longer.\n ' '' ''
The above output shows all of the text. Next, you will extract specific sections of the website.
Extracting Key Elements
It is easy to extract elements, such as the title of the product, with the corresponding HTML tag. To find the class of the specific tag, right-click on the element and select Inspect. An example is shown below.
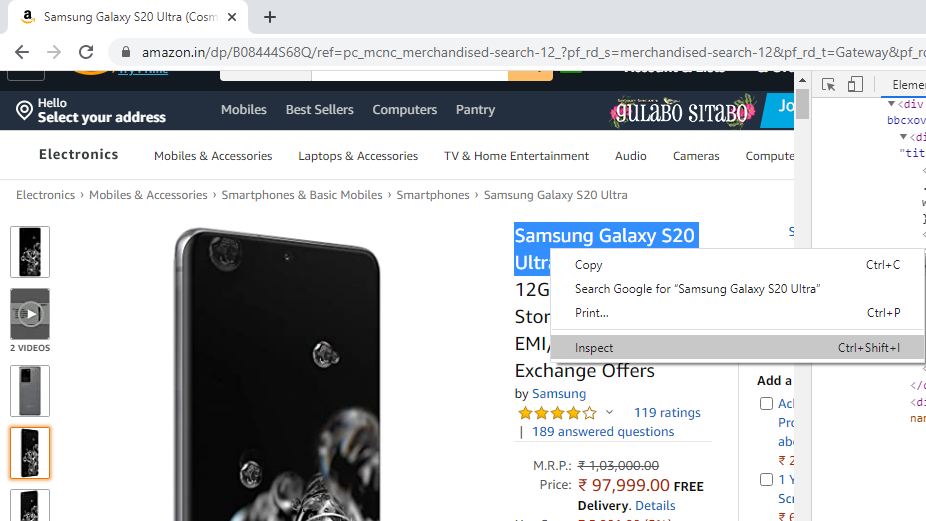
The above step will generate the following display, which provides the ID of the element you want to extract.
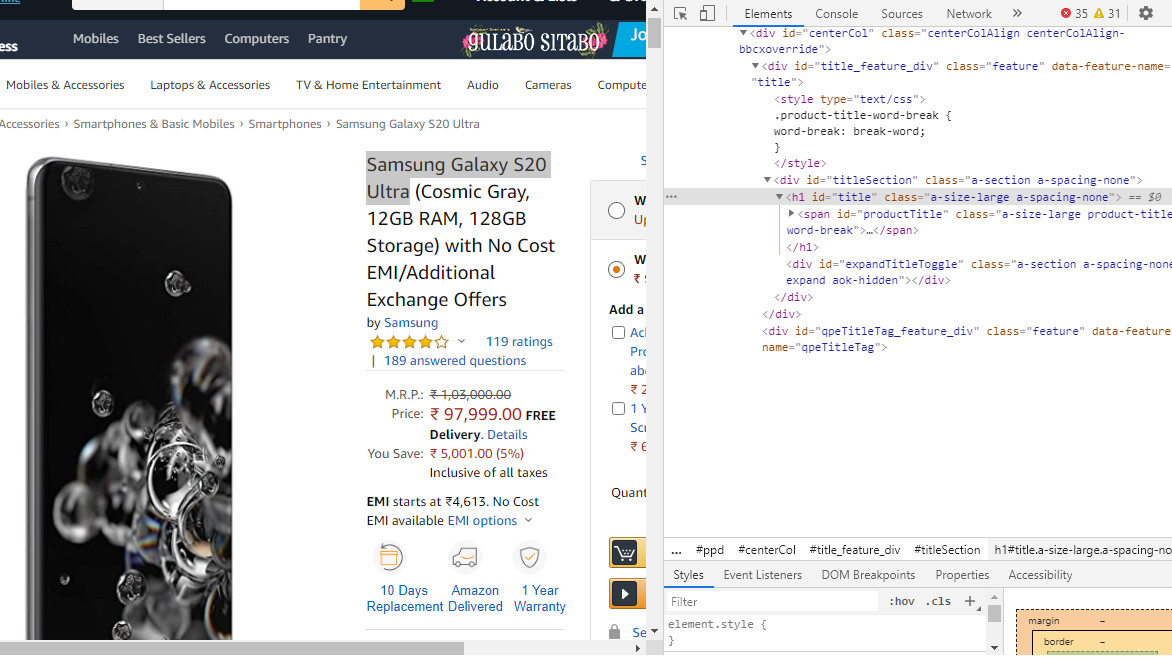
In the code below, pass the ID of the title, 'h1#title', as an argument in the code to extract the title of the product.
title_html <- html_nodes(webdata, 'h1#title')
title <- html_text(title_html)
head(title)
Output:
'\n\n\n\n\n\n\n\n\nSamsung Galaxy S20 Ultra (Cosmic Gray, 12GB RAM, 128GB Storage) with No Cost EMI/Additional Exchange Offers\n\n\n\n\n\n\n\n\n\n\n\n\n'
The output above provides the title but also prints white space and unwarranted characters. You can remove these with the str_replace_all() function.
str_replace_all(title, "[\r\n]" , "")
Output:
Samsung Galaxy S20 Ultra (Cosmic Gray, 12GB RAM, 128GB Storage) with No Cost EMI/Additional Exchange Offers
Next, extract the price of the product. The HTML class of the price is span#priceblock_ourprice, which is used in the code below to extract the product price.
price_html <- html_nodes(webdata, 'span#priceblock_ourprice')
price <- html_text(price_html)
str_replace_all(price, "[\r\n]" , "")
Output:
'₹ 97,999.00'
The output above shows the price of the product in Indian currency. Next, extract the product description.
desc_html <- html_nodes(webdata, 'div#productDescription')
prod_desc <- html_text(desc_html)
prod_desc <- str_replace_all(prod_desc, "[\r\n\t]" , "")
prod_desc <- str_trim(prod_desc)
head(prod_desc)
Output:
'Style name:with No Cost EMI/Additional Exchange Offers | Colour:Cosmic GrayGalaxy S20 series introduce the next generation of mobile innovation. Completely redesigned to remove interruptions from your view. No notch, no distractions. Precise laser cutting, on-screen security, and a Dynamic AMOLED that\'s easy on the eyes make the Infinity-O Display the most innovative Galaxy screen yet. Use the Ultra Wide Camera to take stunning, cinematic photos with a 123 degree field of vision.'
The next step is to scrape the color of the product, which is done with the code below.
color_html <- html_nodes(webdata, 'div#variation_color_name')
color_html <- html_nodes(color_html, 'span.selection')
color <- html_text(color_html)
color <- str_trim(color)
head(color)
Output:
'Cosmic Gray'
An important thing customers look for when browsing products on a website is the product rating. The HTML class of the rating in this case is span#acrPopover, which is used as an argument in the code below.
rate_html <- html_nodes(webdata, 'span#acrPopover')
rate <- html_text(rate_html)
rate <- str_replace_all(rate, "[\r\n\t]" , "")
rate <- str_trim(rate)
head(rate)
Output:
'4.0 out of 5 stars'
The rating of the product is a decent four out of five. However, the rating alone is not sufficient, as it needs to be understood together with the number of customers who gave a rating. This is achieved with the code below, where the HTML class is span#acrCustomerReviewText.
number_ratings <- html_nodes(webdata, 'span#acrCustomerReviewText')
number_ratings <- html_text(number_ratings)
number_ratings <- str_replace_all(number_ratings, "[\r\n\t]" , "")
number_ratings <- str_trim(number_ratings)
head(number_ratings)
Output:
'106 ratings'
Conclusion
In this guide, you have learned methods of web scraping with R. You also learned how to extract, pre-process, and print key items of interest.
To learn more about data science using 'R', please refer to the following guides:


Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.