

Explore Python Libraries: HTTPX
Sep 15, 2020 • 11 Minute Read
Introduction
The HTTPX library provides important features available in the Requests library as well as support for both HTTP/1.1 and HTTP/2. You can have a look at HTTPX's website to know what features HTTPX has in its pocket. In this guide, you will explore the following HTTPX topics with practical examples:
- Passing data in URL
- Setting custom headers
- Accessing different forms of data
- Posting different forms of data
- Handling redirections and timeout
All of the code in this guide assumes that the HTTPX library has been installed and successfully imported in your current working environment as import httpx.
Passing Data in URL
Suppose you want to fetch the stock stats of a company from the Yahoo! Finance website. The associated URL will be https://finance.yahoo.com/quote/ABXY/key-statistics?p=ABXY where "ABXY" is the company's registered abbreviation. Notice that the URL consists of a key-value pair where the key is "p" and the value is "ABXY". So if you want to fetch stock stats for another company, all you need to do is replace "ABXY" with your required company's registered abbreviation.
To learn this concept practically, you can fetch the stock stats of PS (NASDAQ: Pluralsight). Start by forming a dictionary as shown:
eq = {'p': 'PS'}
And finally, use httpx.get method and provide the complete URL including the eq variable:
r = httpx.get('https://finance.yahoo.com/quote/'+eq['p']+'/key-statistics', params=eq)
You can view the resulted URL using url attribute as shown:
print(r.url)
# https://finance.yahoo.com/quote/PS/key-statistics?p=PS
Setting Custom Headers
If you want to let the client and server pass additional data with an HTTP request, you can set custom HTTP headers using HTTPX library. For instance, consider YouTube whose headers can be extracted as shown:
url = 'https://youtube.com'
r = httpx.get(url)
print(r.headers)
The result of the above code is the following YouTube headers:
Headers([('x-frame-options', 'SAMEORIGIN'), ('strict-transport-security', 'max-age=31536000'), ('expires', 'Tue, 27 Apr 1971 19:44:06 GMT'), ('x-content-type-options', 'nosniff'), ('content-encoding', 'gzip'), ('p3p', 'CP="This is not a P3P policy! See http://support.google.com/accounts/answer/151657?hl=en-GB for more info."'), ('content-type', 'text/html; charset=utf-8'), ('cache-control', 'no-cache'), ('date', 'Sat, 27 Jun 2020 07:17:08 GMT'), ('server', 'YouTube Frontend Proxy'), ('x-xss-protection', '0'), ('set-cookie', 'YSC=QxCnrEi_49U; path=/; domain=.youtube.com; secure; httponly; samesite=None'), ('set-cookie', 'VISITOR_INFO1_LIVE=L4qLJ2-3U18; path=/; domain=.youtube.com; secure; expires=Thu, 24-Dec-2020 07:17:08 GMT; httponly; samesite=None'), ('set-cookie', 'GPS=1; path=/; domain=.youtube.com; expires=Sat, 27-Jun-2020 07:47:08 GMT'), ('alt-svc', 'h3-27=":443"; ma=2592000,h3-25=":443"; ma=2592000,h3-T050=":443"; ma=2592000,h3-Q050=":443"; ma=2592000,h3-Q046=":443"; ma=2592000,h3-Q043=":443"; ma=2592000,quic=":443"; ma=2592000; v="46,43"'), ('transfer-encoding', 'chunked')])
Notice, the default value of the content-encoding header is gzip. What if you want to go with any other alternative like br?
To update the value of a header, store the new value in a dictionary and pass the dictionary to the headers argument of the get method as shown:
headers = {'accept-encoding': 'br'}
print(httpx.get(url, headers=headers).headers) # The updated content encoding is br
This updated header is shown below:
Headers([
...
('content-encoding', 'br'),
...
Accessing Different Forms of Data
You can use the HTTPX library to fetch text, image, and JSON data. In this section, you will learn to fetch text and image data both small and large in size. For larger data you can perform streaming, which will be explained further in this section.
1. Fetching Text Data
Suppose you want to fetch data in the HTML format from a webpage that consists of not more than 5-10 lines of text as shown in the image:
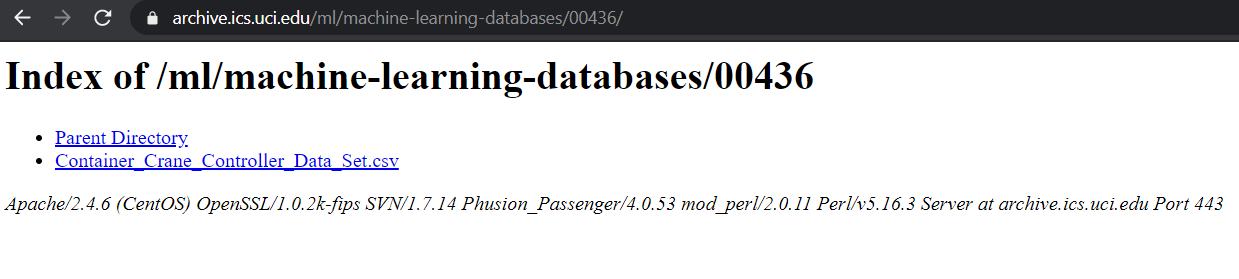
To do so, pass the URL inside the httpx.get method and later use the text attribute as shown:
# https://archive.ics.uci.edu/ml/datasets/Container+Crane+Controller+Data+Set
fetch = httpx.get('https://archive.ics.uci.edu/ml/machine-learning-databases/00436/')
print(fetch.text)
Output:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<html>
<head>
<title>Index of /ml/machine-learning-databases/00436</title>
</head>
<body>
<h1>Index of /ml/machine-learning-databases/00436</h1>
<ul><li><a href="/ml/machine-learning-databases/"> Parent Directory</a></li>
<li><a href="Container_Crane_Controller_Data_Set.csv"> Container_Crane_Controller_Data_Set.csv</a></li>
</ul>
<address>Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips SVN/1.7.14 Phusion_Passenger/4.0.53 mod_perl/2.0.11 Perl/v5.16.3 Server at archive.ics.uci.edu Port 443</address>
</body></html>
2. Streaming Text Data
To fetch large text data, you can perform streaming, i.e. fetch a limited amount of data at a time until you reach the end of the page. To understand this topic, suppose you want to extract all the text data from the Wikipedia page about Ghostbusters. To do so, you could fetch data line by line inside a for loop that is nested inside the httpx.stream method as shown:
with httpx.stream("GET", "https://en.wikipedia.org/wiki/Ghostbusters") as r:
count = 0
for line in r.iter_lines():
# print(line)
count += 1
print(count)
# 1166
In the above code, the print(line) statement is commented. You can uncomment it and observe the output as it streams. The last line print(count) describes the total number of lines (1166) fetched during the stream.
3. Fetching Image Data
The process of fetching an image data is similar to that of a text data. However, the only difference is how you read it once you get it in your Python environment. Consider that you need to fetch a penguin image from the Pixabay website. To do so, pass the image URL inside the httpx.get method and later use PIL and io methods to read and display the data as shown:
from PIL import Image
from io import BytesIO
# https://pixabay.com/photos/penguin-figure-christmas-santa-hat-1843544/
g = httpx.get('https://cdn.pixabay.com/photo/2016/11/20/19/02/penguin-1843544_1280.jpg')
Image.open(BytesIO(g.content)).show()

4. Streaming Image Data
You can use the httpx.stream method to fetch large image data. The only difference from that of streaming text data is that this time the for loop iterates over iter_bytes as shown:
with httpx.stream("GET", "https://cdn.pixabay.com/photo/2016/11/20/19/02/penguin-1843544_1280.jpg") as r:
for data in r.iter_bytes():
print(data)
Posting Different Forms of Data
HTTPX can be used to post data inside a form available on a webpage. In this section, you will learn how to upload text and file data to a webpage.
1. Uploading Text Data
Suppose you want to write "Hello, World!" on a webpage using HTTPX. The input area would look like the one as shown here in the green color:
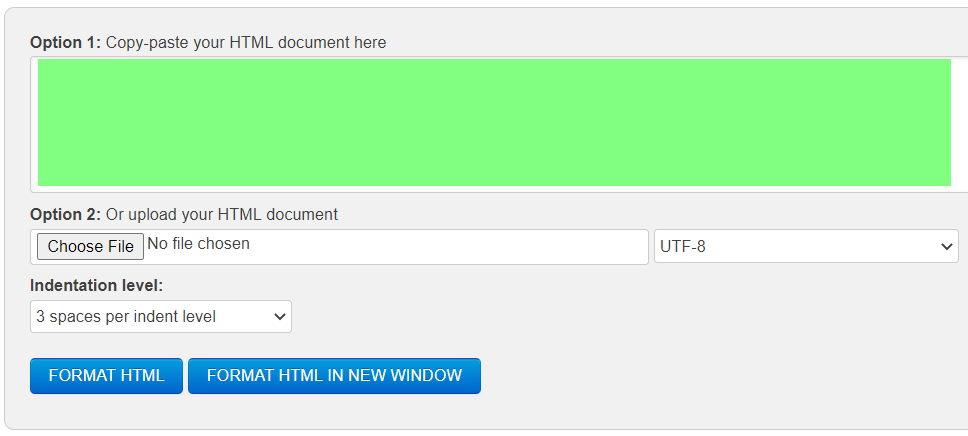
To do so, use the post method and provide the information inside the data argument as shown:
data = {'htmlString': 'Hello, World!'}
# Locate a correct node, for me it is "htmlString"
r = httpx.post("<URL>", data=data)
print(str(r.content).replace('\\n','').replace('\\t','').replace('\\r',''))
The above code results in an HTML output. Since the output is too big, given below is the properly formatted webpage with the "Hello, World!" string in the desired box:

2. Uploading a File
There are many websites where you have to upload a file on their server. Here's one instance as highlighted in the green box:
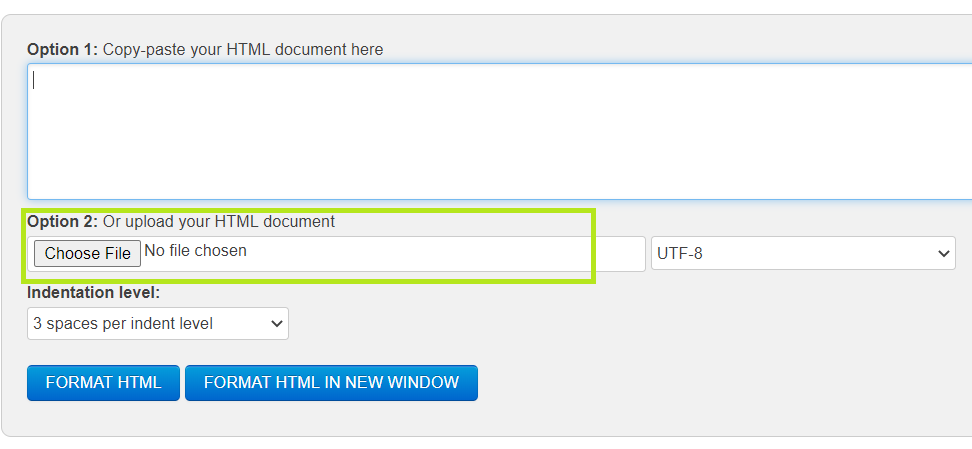
To upload a complete file rather than just writing a string, you can use the files argument of the post method. Assume you have a HTML file upload.html stored on your drive. You can upload it on this webpage using the given code:
file = {'htmlFile': open('upload.html', 'rb')}
# Locate a correct node, for me it is "htmlFile"
r = httpx.post("<URL>", files=file)
print(str(r.content).replace('\\n','').replace('\\t','').replace('\\r',''))
You can verify that the data has been successfully uploaded by checking the console result.
Handling Redirections and Timeout
Have you ever noticed that when you type "https://msn.com" in a browser, it may not necessarily retain its URL as-it-is? There are good chances that you may be redirected based on the geographical region from where you are trying to access the website. For instance, run the following code and check your output:
r = httpx.get('https://msn.com')
print(r.url)
For me it is https://www.msn.com/en-in/, but for you, the last two characters may differ. But, the point is the original URL has been changed and you are redirected to a new one. However, the good news is that you can control whether redirection should take place or not. If you don't need a redirection from your original URL then use allow_redirects=False inside the get method as shown:
r = httpx.get('https://msn.com', allow_redirects=False)
print(r.url)
# https://msn.com
Also, you can control how long should it take for a website to load before the program throws a timeout error. You can specify custom timeout value by using the timeout parameter as shown:
r = httpx.get('https://msn.com', allow_redirects=False, timeout=1)
print(r.url)
# https://msn.com
In the above code, if the URL is not reached before one second, the program will result in a ConnectError.
Conclusion
You have now learned the basics of HTTPX library by exploring its get, post, and stream methods.


Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.