

Using Redis on Cloud? Here are ten things you should know
It’s hard to operate stateful distributed systems at scale and Redis is no exception. This article covers Redis best practices, tips & tricks.
Jun 08, 2023 • 9 Minute Read

It’s hard to operate stateful distributed systems at scale, and Redis is no exception. Managed databases make life easier by taking on much of the heavy lifting, but you still need a sound architecture and to apply best practices — both on the server (Redis) as well as client (application).
This blog post covers a range of Redis-related best practices, tips and tricks including cluster scalability, client side configuration, integration, and metrics. Although I will be citing Amazon MemoryDB and ElastiCache for Redis from time to time, most (if not all) will be applicable to Redis clusters in general.
This is not meant to be an exhaustive list by any means. I simply chose ten since it’s a nice, wholesome number!
Let’s dive right in and start off with what options you have in terms of scaling your Redis cluster.

Your keys to a better career
Get started with ACG today to transform your career with courses and real hands-on labs in AWS, Microsoft Azure, Google Cloud, and beyond.
1. Scalability options
You can either scale up or down:
- Scaling Up (Vertical) - You can increase the capacity of individual nodes/instances for e.g. upgrade from Amazon EC2
db.r6g.xlarge typetodb.r6g.2xlarge - Scaling Out (Horizontal) - You can add more nodes to the cluster
The requirement to scale out might be be driven by few reasons.
If you need to tackle a read heavy workload, you can choose to add more replica nodes. This applies both for a Redis clustered setup (like MemoryDB) or a non-clustered primary-replica mode as in the case of ElastiCache with cluster mode disabled.
If you want to increase write capacity, you will find yourself limited by the primary-replica mode and should opt for a Redis Cluster based setup. You can increase the number of shards in your cluster - this is because only primary nodes can accept writes and each shard can only have one primary.
This has the added benefit of increasing the overall high availability as well.
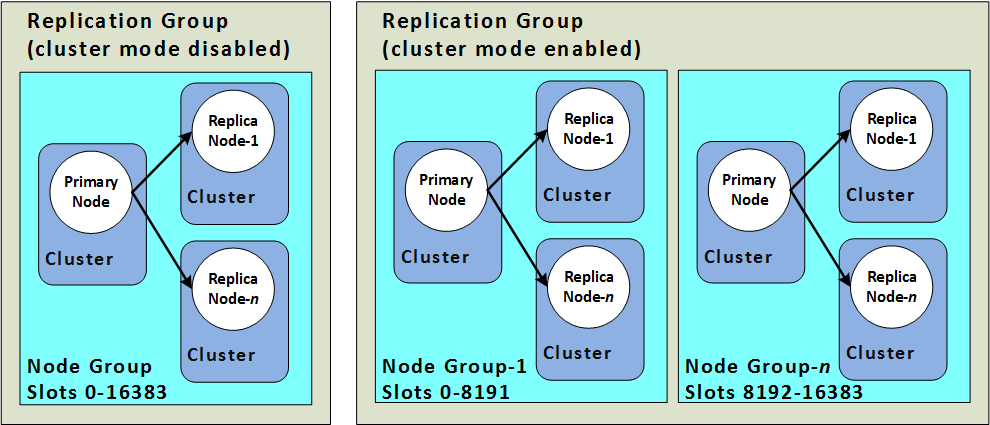
Figure 1: Redis (cluster mode disabled) and Redis (cluster mode enabled) clusters - ElastiCache for Redis documentation
2. After scaling your cluster, you better use those replicas!
The default behaviour in most Redis Cluster clients (including redis-cli) is to redirect all reads to the primary node. If you have added read replicas to scale read traffic, they are going to sit idle!
You need to switch to READONLY mode to ensure that the replicas handle all the read requests are not just passive participants. Make sure to configure your Redis client appropriately - this will vary with the client and programming language.
For example, in the Go Redis client, you can set ReadOnly to true:
client := redis.NewClusterClient(
&redis.ClusterOptions{
Addrs: []string{clusterEndpoint},
ReadOnly: true,
//..other options
})
To optimize further, you can also use RouteByLatency or RouteRandomly, both of which automatically turn on ReadOnly mode.
You can refer to how this works for Java clients such as Lettuce
3. Be mindful of consistency characteristics when using read replicas
There is a chance that your application might read stale data from replicas - this is Eventual Consistency in action. Since the primary to replica node replication is asynchronous, there is a chance that the write you sent to a primary node has not yet reflected in the read replica.
This is likely when you have a high number of read replicas specially across multiple availability zones. If this is unacceptable for your use-case, you will have to resort to using primary nodes for reads as well.
The ReplicationLag metric in MemoryDB or ElastiCache for Redis can be used to check how far behind (in seconds) the replica is in applying changes from the primary node.
What about Strong Consistency?
In case of MemoryDB, the reads from primary nodes are strongly consistent. This is because the client application receives a successful write acknowledgement only after a write (to the primary node) is written to a durable Multi-AZ Transaction Log.
4. Remember, you can influence how your keys are distributed across a Redis cluster
Instead of using consistent hashing (like a lot of other distributed databases), Redis uses the concept of hash slots. There are 16384 slots in total, a range of hash slots is assigned to each primary node in the cluster and each key belongs to a specific hash slot (thereby assigned to a particular node). Multi-key operations executed on a Redis cluster cannot work if keys belong to different hash slots.
But, you are not completely at the mercy of the cluster! It's possible to influence the key placement by using hash tags. Thus, you can ensure that specific keys have the same hash slot.
For example, if you are storing orders for customer ID 42 in a HASH named customer:42:orders and the customer profile info in customer:42:profile, you can use curly braces {} to define the specific substring which will be hashed.
In this case, our keys are {customer:42}:orders and {customer:42}:profile - {customer:42} now drives the hash slot placement. Now we can be confident that both these keys will be in the same hash slot (hence same node).
5. Did you think about scaling (back) in?
Your application was successful, it has a lot of users and traffic. You scaled out the cluster and things are still going great. Awesome!
But what if you need to scale back in?
You need to be careful about a few things before you do that:
- Is there enough free memory on each of the nodes?
- Can this be done during non-peak hours?
- How will it affect your client applications?
- Which metrics can you monitor during this phase? (e.g.
CPUUtilization,CurrConnectionsetc.)
Refer to some of the best practices in the MemoryDb for Redis documentation to better plan for scaling in.
6. When things go wrong....
Let’s face it, failures are enviable. What’s important is whether you are prepared for them? In case of your Redis cluster, here are some things to think about:
- Have you tested your application/service behaviour in face of failures? If not, please do! With MemoryDB and ElastiCache for Redis, you can leverage the Failover API to simulate a primary node failure and trigger a failover.
- Do you have replica nodes? If all you have is one shard with a single primary node, you are certainly going to have downtime if that node fails.
- Do you have multiple shards? If all you have is one shard (with primary and replica), in case of primary node failure of that shard, the cluster cannot accept any writes.
- Do your shards span multiple availability zones? If you have shards across multiple AZs, you will be better prepared to tackle AZ failure.
In all cases, MemoryDB ensures that no data is lost during node replacements or failover
Unable to connect to Redis, help!
Tl;DR: It's probably the networking/security configuration
This is something which trips up folks all the time! With MemoryDB and ElastiCache, your Redis nodes are in a VPC. If you have a client application deployed to a compute service such as AWS Lambda, EKS, ECS, App Runner etc., you need to ensure you have the right configuration - specifically in terms of VPC and Security Group(s).
This might vary depending on the compute platform you are using. For example, how you configure a Lambda function to access resources in a VPC is slightly different compared to how App Runner does it (via a VPC Connector), or even EKS (although conceptually, they are the same).
8. Redis 6 comes with Access Control Lists - use them!
There is no excuse to not apply authentication (username/password) and authorization (ACL based permission) to your Redis cluster. MemoryDB is Redis 6 compliant and supports ACL. However, to comply with older Redis versions, it configures a default user per account (with username default) and an immutable ACL called open-access. If you create a MemoryDB cluster and associate it with this ACL:
- Clients can connect without authentication
- Clients can execute any command on any key (no permission or authorization either)
As a best practice:
- Define an explicit ACL
- Add users (along with passwords), and
- Configure access strings as per your security requirements.
You should monitor authentication failures. For example, the AuthenticationFailures metric in MemoryDB gives you the total number of failed authenticate attempts - set an alarm on this to detect unauthorized access attempts.
Don't forget perimeter security
If you've configured TLS on the server, don't forget to use that in your client as well! For example, using Go Redis:
client := redis.NewClusterClient(
&redis.ClusterOptions{
Addrs: []string{clusterEndpoint},
TLSConfig: &tls.Config{MaxVersion: tls.VersionTLS12},
//..other options
})
Not using it can give your errors that's not obvious enough (e.g. a generic i/o timeout) and make things hard to debug - this is something you need to be careful about.
9. There are things you cannot do
As a managed database service, MemoryDB or ElastiCache restrict access to some of the Redis commands. For example, you cannot use a subset of the CLUSTER related commands since the cluster management (scale, sharding etc.) is taken of by the service itself.
But, in some cases, you might be able to find alternatives. Think of monitoring slow running queries as an example. Although you cannot configure latency-monitor-threshold using CONFIG SET, you can set the slowlog-log-slower-than setting in the parameter group and then use slowlog get to compare against it.
10. Use connection pooling
Your Redis server nodes (even powerful ones) have finite resources. One of them is ability to support a certain number of concurrent connections. Most Redis clients offer connection pooling as a way to efficiently manage connections to the redis server. Re-using connections not only benefits your Redis server, but client side performance is improved due to less overhead - this is critical in high volume scenarios.
ElastiCache provides a few metrics you can track:
CurrConnections: the number of client connections (excluding ones from read replicas)NewConnections: the total number of connections that have been accepted by the server during a specific period.
11. (Bonus) Use the appropriate connection mode
This one is kind of obvious, but I am going to call it out anyway since this is one of the most common "getting started" mistakes I witness folks make.
The connection mode that you use in your client application will depend on whether you're using a standalone Redis setup, a Redis Cluster (most likely). Most Redis clients draw a clear distinction between them. For example, if you are using the Go Redis client with MemoryDB or Elasticache cluster mode enabled), you need to use NewClusterClient (not NewClient):
redis.NewClusterClient(&redis.ClusterOptions{//....})Interestingly enough, there is UniversalClient option which is a bit more flexible (at the time of writing, this is in Go Redis v9)
If you don't use the right mode of connection, you will get an error. But sometimes, the root cause will be hidden behind a generic error message - so you need to be watchful.
Conclusion
The architectural choices you make will ultimately be driven by your specific requirements. I would encourage you to explore the following blog posts for a deeper dive into performance characteristics of MemoryDB and ElastiCache for Redis and how they might impact the way design your solutions:
Abhishek is currently a Principal Developer Advocate at AWS with a focus on Databases. Over the course of his career, he has worn multiple hats including engineering, product management and developer advocacy. Most of his work has revolved around open-source technologies including distributed data systems and cloud-native platforms. Abhishek is also an open-source contributor, avid blogger and author.


Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.